Can a Machine Read Your Mind?
How AI systems are beginning to understand implicit intent — and what that means for the future of human connection.

When do you feel most clicked with someone? For me, it's the magical moment when someone effortlessly completes my sentence or instantly understands my unspoken thoughts. That feeling of deep human connection — rooted in shared experience and profound empathy — is what makes us feel truly understood.
Understanding implicit intent — unspoken or indirectly expressed intentions — is a significant challenge for AI. Humans develop this ability through self-awareness and emotional maturity, often described as theory of mind. This capacity to empathize, relate, and go beyond what is made explicit makes human connections profound.
I've spent years building systems that predict user intent at Credit Karma, TikTok, using multimodal data for Amazon Alexa — propensity models, recommendation engines, behavioral classifiers. We got good at predicting what users would do. But predicting what they actually mean? That's a different problem.
The future of AI may hold this possibility. As LLMs and multimodal systems evolve, they're beginning to grasp what we mean, not just what we say. Will our AI assistants one day become the “bosom friend” who understands us better than anyone else?
The Gap
The failures are systematic, not occasional.
In multi-turn conversations, errors compound — a “snowball effect” where early misunderstandings cascade into progressively worse responses. When someone says “What should I do next?” mid-conversation, models give generic answers instead of grounding in what came before. When someone trails off with “I guess that's it then…” models miss the resignation entirely.
Even with 1M+ token context windows, performance degrades on the tasks that matter most: tracking implicit threads across long conversations, detecting emotional subtext, knowing when to ask rather than guess.
AI is going agentic. Systems that don't just answer questions but take actions — booking travel, managing projects, coordinating workflows. An agentic AI that misunderstands implicit intent doesn't give a wrong answer. It takes a wrong action.
How Models Try to Capture Intent
Three architectural approaches dominate current attempts to give models access to implicit user signals. Each makes a different tradeoff between richness and scalability.
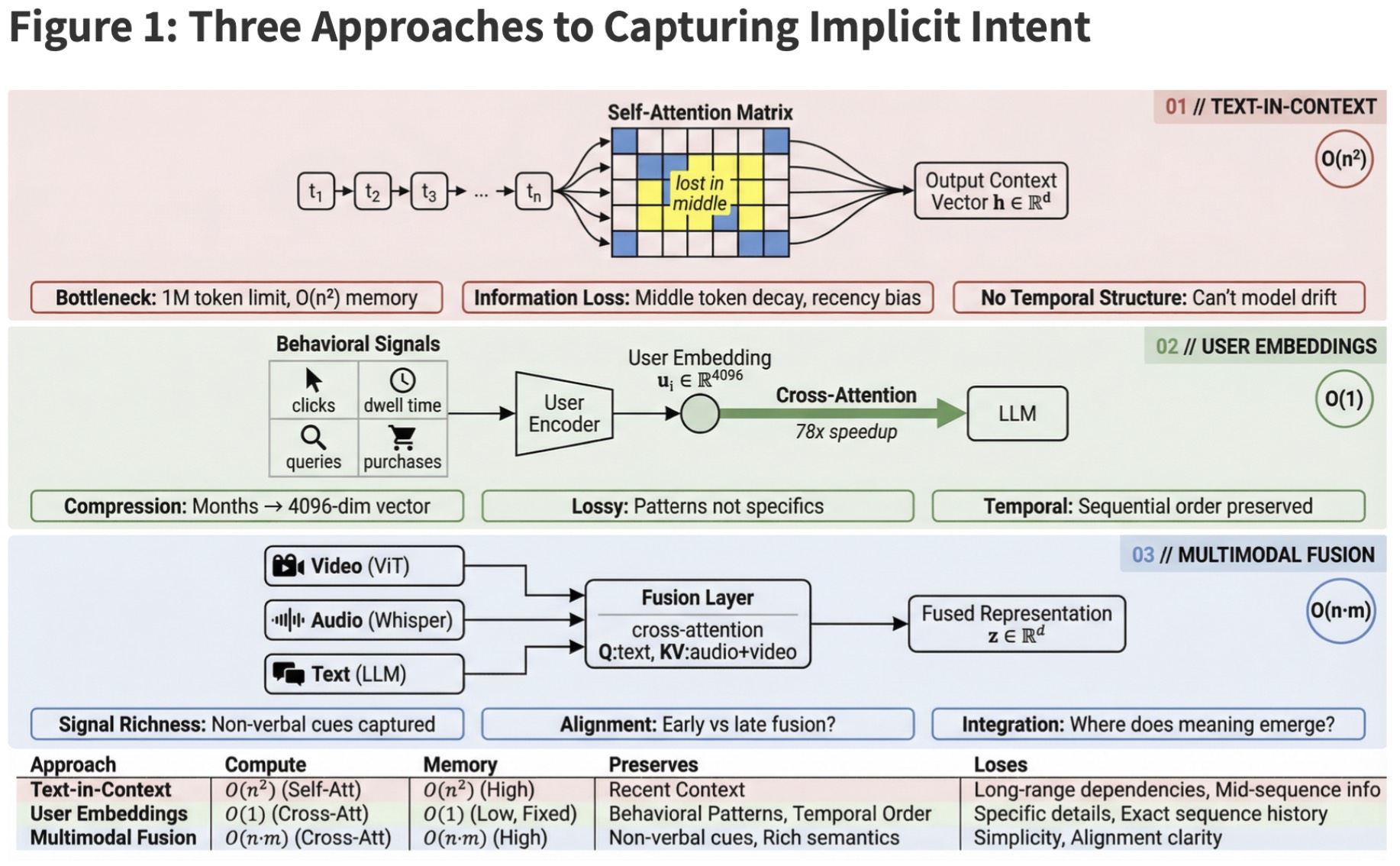
The naive baseline: stuff conversation history into the prompt. Even 1M token windows fill up fast, and raw transcripts are noisy. The model sees a bag of messages, not a trajectory of evolving needs.
Compress behavioral signals — clicks, queries, dwell time — into dense vectors. Google’s USER-LLM achieves 78x computational savings while preserving predictive power. The tradeoff: embeddings are lossy. General patterns survive; specific context doesn’t.
Aligns text, audio, and visual inputs into a shared representation space. When someone says “I guess that works” while frowning with a hesitant tone, each modality carries part of the meaning.
The uncomfortable truth: no current architecture solves the fundamental tension. Compression gains efficiency but loses nuance. Raw history preserves detail but doesn't scale. Every approach is a bet on which tradeoffs matter less.
Two Theories of the Gap
Why is implicit intent so hard? Two camps offer starkly different explanations — and the answer shapes what's possible next.
The optimists point to representational convergence. A provocative line of research suggests that neural networks — regardless of architecture or training data — are converging toward shared representations of reality. If this continues, AI systems might develop generalized understanding of human behavior that transcends individual training. Intent understanding would emerge naturally from increasingly faithful models of how humans actually think.
The skeptics see something darker. LLMs aren't learning world models — they're learning “bags of heuristics.” The Othello experiments that seemed to show emergent world-modeling? On closer inspection, the models learned prediction rules that work for training data but fail on edge cases. They're not understanding the game; they're pattern-matching move sequences.
When an LLM appears to grasp what you mean, it may be executing sophisticated syntactic pattern-matching that mimics semantic understanding without achieving it. The appearance of empathy without the substance.
I think both camps are partially right, which is the uncomfortable part.
What Becomes Possible
Set aside the philosophical debate about “real” understanding. What happens when the functional approximation gets good enough?
Persistent memory changes everything. An AI that remembers not just your words but your patterns — what you ask when you're stressed, what you avoid when you're overwhelmed, what you actually want when you say “whatever's fine.” Not a chatbot with a database. Something closer to a friend who's been paying attention.
Multimodal reading adds depth. A September 2025 study found GPT-4 predicting emotions from video with accuracy matching human evaluators — and crucially, the structure of its emotion ratings converged with human patterns. Now combine that with persistent memory: an AI that reads your face, remembers your patterns, and tracks how your feelings evolve across conversations.
Preference prediction extends beyond text. Models are getting good at predicting what we want without understanding why we want it — in images, in music, in interface design.
An AI assistant that remembers your communication patterns across months, reads emotional subtext from your voice and face, anticipates your needs based on context you never explicitly provided, and generates responses tuned to preferences you never articulated. Every piece of that exists in research labs today.
The Question I Can't Answer
I've built systems that predict intent from behavioral signals — clicks, purchases, time-on-page. The models work. Users convert. Metrics improve.
But I've never built a system that made someone feel understood.
The research trajectory is clear: multimodal inputs, persistent memory, better reasoning, richer benchmarks. Each advance closes the gap between what we say and what machines infer. We will almost certainly build AI that responds to implicit intent better than most humans bother to.
When your AI assistant remembers your preferences, anticipates your needs, responds to your unspoken frustrations with exactly the right tone — will that feel like connection? Or will it feel like a very sophisticated mirror, reflecting back what you want to see without anyone on the other side?
I don't know. But I suspect we're going to find out soon.
From Understanding to Expression
At DecodeNetwork.AI, we're applying these same principles to a different problem: can AI-generated art capture something essential about who you are?
Research consistently shows that aesthetic preferences aren't random — they're deeply tied to personality. Studies using the Big Five personality framework have found that Openness to Experience predicts preference for abstract and challenging art, while Agreeableness correlates with preference for representational works. These aren't weak correlations — they're stable patterns that persist across cultures and demographics.
We're building systems that work in reverse: given behavioral signals from how users interact with AI art platforms — what they create, what they save, what they share, how long they dwell — can we predict the visual styles that resonate with their implicit sense of self? The goal isn't just recommendation. It's matching people with AI-generated imagery that feels like a mirror of their aesthetic soul.
Sources
- Zhang, Y., et al. (2025). Bridging the Gap Between LLMs and Human Intentions. arXiv:2502.09101.
- Spiegel, B. (2025). AGI Is Not Multimodal. The Gradient.
- Huh, M., et al. (2024). The Platonic Representation Hypothesis. arXiv:2405.07987.
- Ning, L., et al. (2024). USER-LLM: Efficient LLM Contextualization with User Embeddings. ACM Web Conference 2025.
- Wu, X., et al. (2023). Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis. arXiv:2306.09341.
- Yang, K., et al. (2025). GPT-4 Emotion Prediction from Video. arXiv (September 2025).
Carol Zhu is CEO and Co-Founder of DecodeNetwork.AI. She previously launched products at AWS AI, TikTok, and Credit Karma — building systems that predict what users want, and thinking deeply about what that means.
Discover what your behavioral signals reveal about you.
Discover Your State →